Signate.jp платформ дээр өгөгдлийн тэмцээнд орсон туршлага, сурсан зүйлсээ энэхүү нийтлэлээр хуваалцая.
Тэмцээнийг зарласан Японы Ийда группээс өгөгдсөн даалгавар болон өгөгдлийн талаар эхлээд танилцуулъя.
1. Өгөгдсөн даалгавар
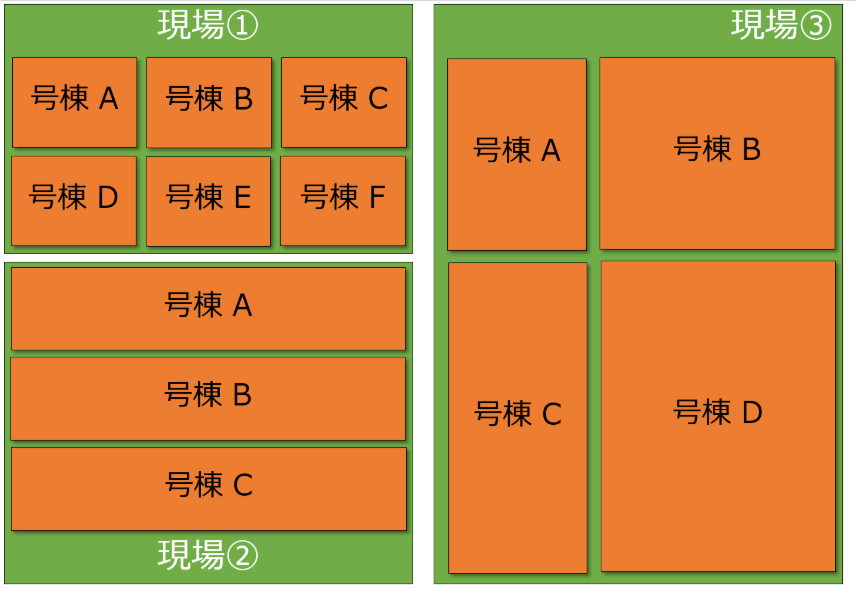
Үндсэн 2 төрлийн өгөгдөл өгөгдсөн бөгөөд 1 нь доорх зурагт харуулсан ногооноор дүрсэлсэн газрын талбайн мэдээлэл, нөгөөх нь тухайн газар дээрх барилгуудын мэдээлэл (улбар шар). Тэмцээнд өгөгдсөн даалгавар нь тухайн газар дээрх барилгуудын үнийг хамгийн оновчтой таамаглах загвар байгуулах юм.
2. Өгөгдөл
Тухайн газар болон барилгатай холбоотой маш олон төрлийн хувьсагчид өгөгдсөн байв. Тухайлбал, газрын байршлын мэдээлэл аль хот, дүүрэг, хороо, тосгонд байрладаг, газрын талбайн хэмжээ, бүсчлэл, дэд бүтэц, цэцэрлэг сургууль хүртэлх зай, ойр байрлах автобусны болон галт тэрэгний буудлын нэр, замын өргөн, барилгын талбайн хэмжээ, өрөөний тоо гэх мэт. Өгөгдлийн заримыг доор харуулав.
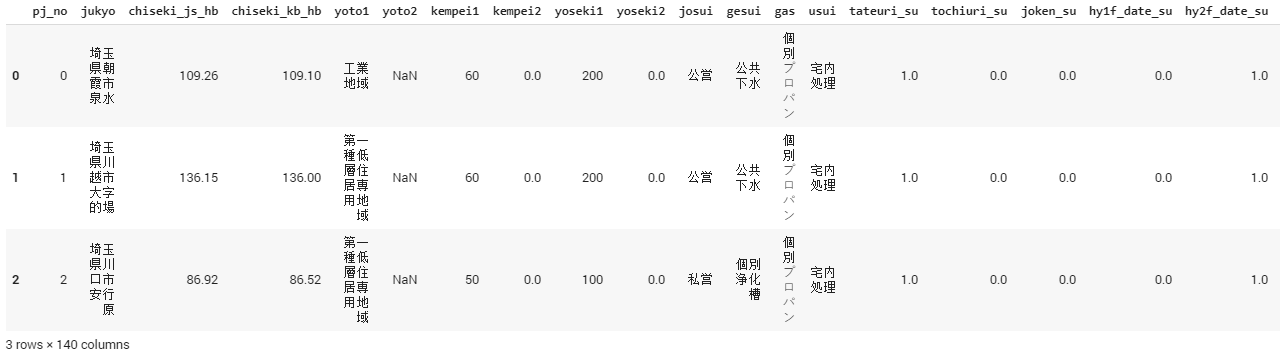

Таамаглах хувьсагч нь “KEIYAKU_PR” — Борлуулах үнэ.
Өгөгдсөн датанууд:
Train genba — Сургалтын дата (2781, 140)
Train goto — Сургалтын дата (6461, 19)
Test genba — Тест дата (1855, 140)
Test goto — Тест дата (4273, 18)
Загварын алдааг хэмжих хэмжүүр — MEAN ABSOLUTE PERCENTAGE ERROR (MAPE) буюу нийт 4273 газрын үнийг бодит утгаас хэдэн хувиар зөрүүлж таасан гэдгээр байр эзлүүлэх юм.
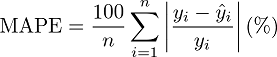
Шалгаруулалтын дүрэм: Өгөгдсөн сургалтын дата дээр загвар байгуулсны дараа тест дата дээр загвараа ашиглан prediction хийх юм. Ингэхдээ тэмцээн явагдах үеийн байр эзлүүлэлт нь нийт тестийн датаны тодорхой хувь дээр (Public LB) оноо гарна гэсэн үг. Тэмцээн дуусах өдөр үлдсэн хувь дээр (Private LB) оноо гарч эцсийн байрыг эзлүүлж ялагчид тодрох дүрэмтэй байв. Иймээс хамгийн сүүлийн өдөр бүх зүйл шийдэгдэнэ гэсэн үг юм. Яг энэ тэмцээний хувьд Public LB дээр 1 дээр байсан хүн 5 руу, 4-р байранд байсан хүн 1-р байранд орж түрүүлсэн. Тиймээс загвараа Overfit болгохгүйн тулд Cross Validation, моделынхоо параметрүүд дээр сайн ажиллах шаардлагатай гэж санагдсан.

3. Хийгдсэн гол гол ажлууд
Хийгдсэн ажлууд дараах хэсгүүдээс бүрдэнэ.
- Өгөгдөл цэвэрлэх
- Өгөгдлийг шинжих
- Feature Engineering
- Ensemble хийх
- Эцсийн таамаглалыг гаргаж авах
Эдгээрийг тус бүрд нь тайлбарлая.
3.1. Өгөгдөл цэвэрлэх
Хамгийн эхлээд Япон хэлнээс бүх датагаа google sheet-н Translate функц ашиглаад англи хэлрүү орчуулж бэлдсэн. Өгөгдсөн дата цэвэрлэгээ нилээн шаардлагатай байсан. Дата цэвэрлэх ажил тийм ч хүсээд байх ажил биш хэдий ч feature engineering хийх, модел сургах гэх мэт дараа дараагийн шатанд нөлөөлөх хамгийн чухал хэсэг болж өгдөг. Дата цэвэрлэх хэсэгт дараах зүйлс ихэвчлэн хийгддэг.
- Давхардлыг арилгах
- Орхигдсон утгуудыг олох, нөхөх (Missing Value, NAs)
- Тогтмол 1 утгатай хувьсагчийг устгах
- Бараг өөрчлөлтгүй буй 0 вариацтай хувьсагчдыг устгах
Орчуулж бэлдсэн 2 датагаа (genba & goto) нийлүүлсний дараа хамгийн эхлээд орхигдсон утгууд нилээн байсан тул тэдгээрийг тоон болон категори гэж ялгаад дараах байдлаар нөхсөн.
- Тоон хувьсагч (Numeric) бол тухайн хувьсагчийн дундаж утгаар
- Категори хувьсагч бол “Missing” гэсэн үгээр
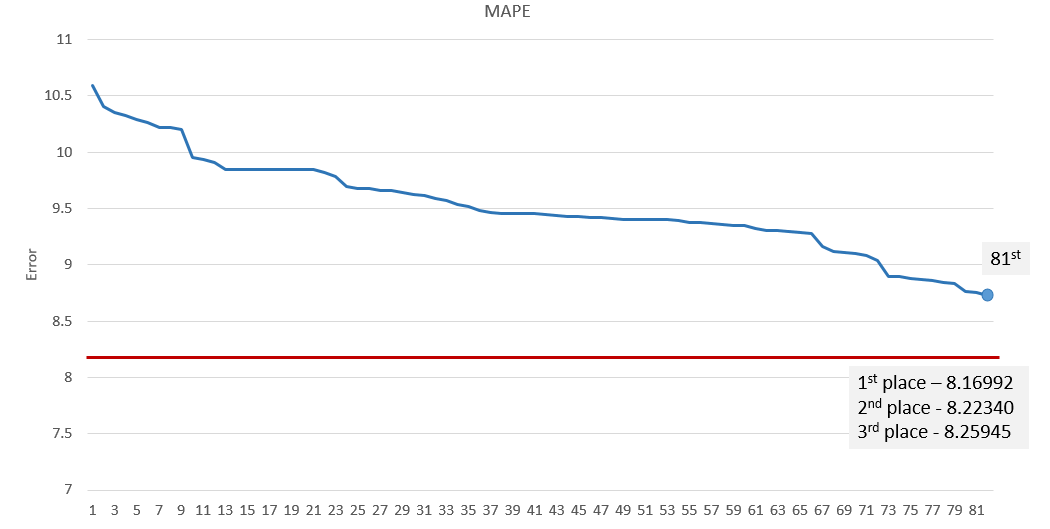
Эхний байдлаар цэвэрлэсэн дата дээрээ энгийн model сургаад submission хийхэд public leaderboard дээр 10.59657 гэсэн оноо авсан. Үүний дараагаар feature engineering, ensemble learning хийх замаар хамгийн сүүлийн (82 дахь) submission-р public leaderboard дээр 8.72744, private leaderboard дээр 8.89042 оноо авсан.
Оноо сайжирахад хамгийн их нөлөөлсөн EDA болон Feature Engineering аргуудыг дараагийн хэсэгт тайлбарлая.
3.2. Өгөгдөл шинжих
Датагаа бэлдэж цэвэрлэсний дараа яг ямар ямар хэв шинжтэй дата байгааг шинжилж үзэх нь загвараа сайжруулах хамгийн зөв аргуудын нэг гэж боддог. Нөгөө талаараа энэ нь feature engineering хийхэд хамгийн их тус болох юм.
Target variable — keiyaku_pr

Таамаглах хувьсагч keiyaku_pr буюу борлуулалтын үнийн тархалт.
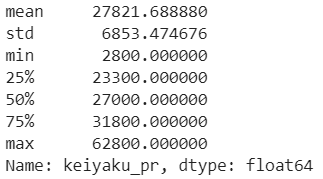
Дундаж утга — 27.8 сая
Стандарт хазайлт — 6.8 сая
Хамгийн их утга — 62.8 сая
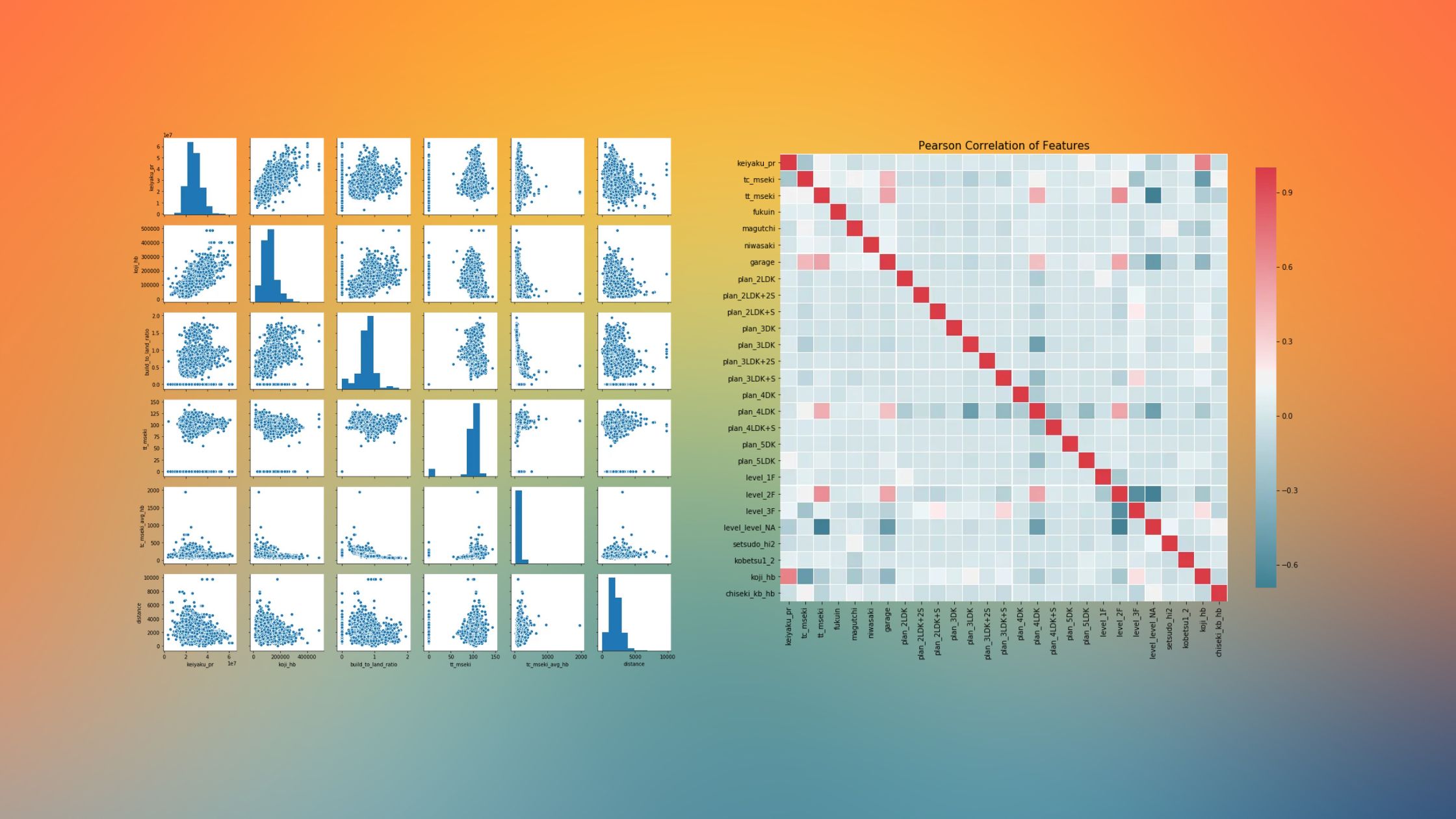
Бусад хувьсагчтай target variable ямар хамааралтай байгааг шинжилсэн Seaborn-ы Pairplot болон Correlation plot-г харуулав.

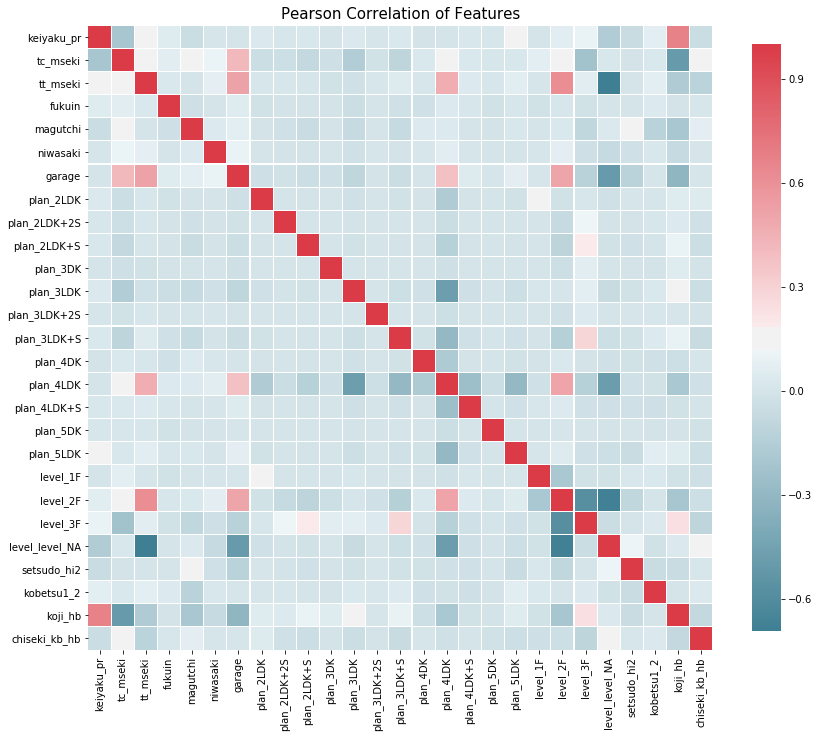
Дээрх шинжилгээнээс хэд хэдэн чухал үр дүнг олж авсан. Koji_hb буюу Японд нийтэд зарлагдсан газрын үнэ (суурь үнэ) гэж урьдчилан тогтоосон үнийн мэдээлэл байдаг бөгөөд тэр нь тухайн газрын зарах үнэтэй хүчтэй хамааралтай байгааг олж мэдсэн. (Корреляци ~ 0.67)
Зарим тоон хувьсагчийн skewness-ийг мөн шинжилж үзсэн.

skewed_feats = num_feat3.apply(lambda x: skew(x.fillna(0))).sort_values(ascending=False)
skewness = pd.DataFrame({‘Skew’ :skewed_feats})
skewness.head(10)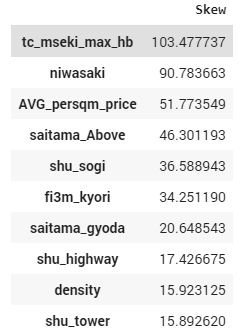
Training хийх явцад skewness-г засах нь алдааг багасгахад чухал нөлөөтэй байсан бөгөөд энэ талаар дараагийн хэсэгт тайлбарлая.
3.3. Feature Engineering
Feature engineering хүрээнд дараах зүйлсийг хийсэн.
- Data transformation — Байгаа дата дээр хувиргалтууд хийх (Log, Box Cox Transformation)
- Feature encoding — Категори хувьсагчдыг encode хийх
- Feature generation — Өгөгдсөн датанаас таргет хувьсагчид нөлөөлж болохуйц шинэ хувьсагчдыг гаргаж авах
- Feature selection — Таргет хувьсагчид нөлөөлөх гол хувьсагчдыг загварт сонгох
3.3.1. Data transformation
Target (Y) хувьсагчийг log(1+y) хувиргалт хийсэн.
y_log = np.log1p(keiyaku_pr)
model.fit(X, y_log)
prediction_log = model.predict(X_test)
prediction = np.expm1(prediction_log)Predictor-үүд буюу (X) — үүдийн хувьд skewness-г засах зорилгоор Box Cox Transformation хийсэн. Энд, загварын үр дүнг хэр сайжруулж байгаагаас хамааран lambda-г 0.15-р сонгосон.
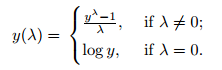
from scipy.special import boxcox1p
skewed_features = skewness.index
lambda = 0.15
for feat in skewed_features:
num_feat_sk = boxcox1p(num_feat, lambda)
Доорх зургаас хувиргалт хийсний дараа илүү нормаль тархалт руу дөхсөнийг харж болно.
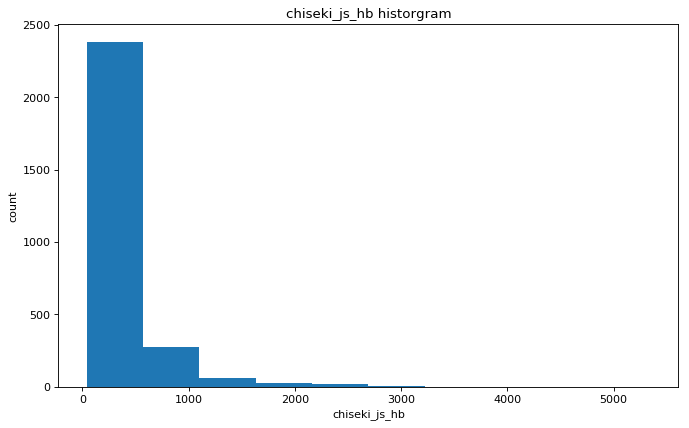
Tranfsormation хийснээр MAPE-г бараг 1 хувиар бууруулсан гэж хэлж болно.
3.3.2. Feature encoding
Энэ хэсэг категори хувьсагчид буюу тухайн газар, барилга байршиж буй хаяг, автобус болон галт тэрэгний буудлын нэр, бүсчлэл (Нэгдүгээр төрлийн бага оврын байшингийн газар・Хоёрдугаар төрлийн бага оврын байшингийн газар・Нэгдүгээр төрлийн орон сууцны талбай・Хоёрдугаар төрлийн орон сууцны талбай・Хагас орон сууцны талбай・Хот суурин газрын талбай・ Худалдааны бүстэй ойролцоох газар・Худалдааны газар・Хагас үйлдвэржилтийн газар …) гэх мэт хувьсагчдыг Encode хийсэн.
3.3.3. Feature generation
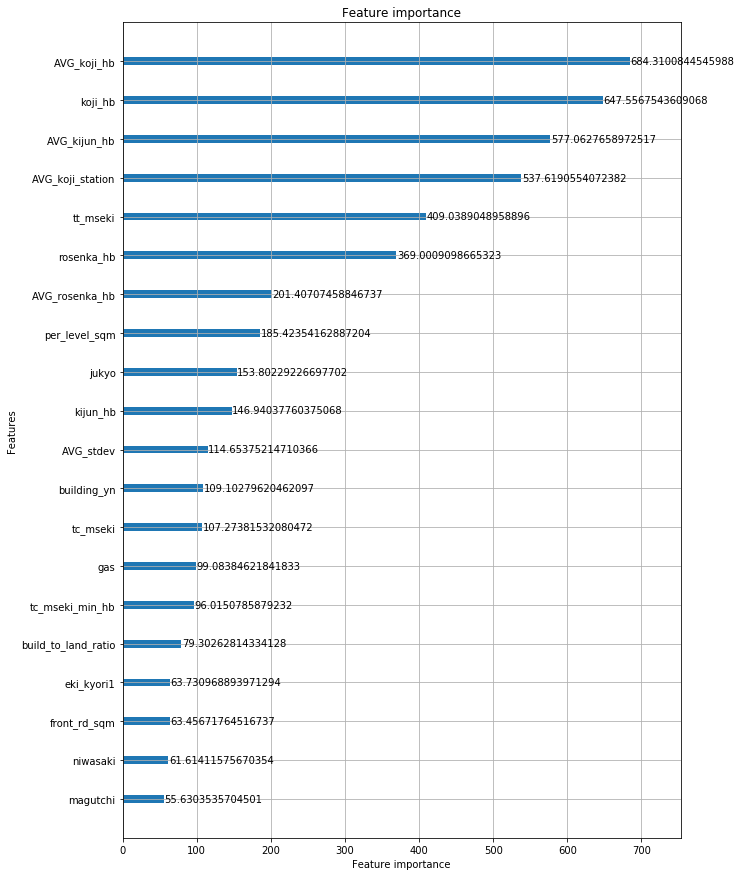
Шинээр хувьсагч үүсгэж моделоо дахин сургах замаар алдаагаа аажим аажмаар бууруулсан гэж хэлж болно. Алдааг бууруулахад нөлөөлсөн дараах шинэ хувьсагчдыг өгөгдсөн датанаас гаргаж авсан.
- Газрын байршлын мэдээллээс газрын үнэтэй хамаарал өндөртэй байршлуудыг тусад нь салгаж хувьсагч болгож оруулсан. Өөрөөр хэлбэл, газрын үнэнд байршил чухал нөлөөтэй байсан гэж хэлж болно. (jukyo)
- Галт тэрэгний буудлын нэрүүдийг салгаж мөн шинэ хувьсагч үүсгэсэн. Аль галт тэрэгний буудалтай ойр байгаагаас хамааран үнэ өөр өөр байсан.
- Барилгын давхрын тоо, өрөөний тоо, талбай зэргээс нэг өрөөний дундаж м2, тухайн зарах газрын талбайн хэдэн хувьд нь барилга байгаа гэх мэт хувьсагчдыг шинээр үүсгэсэн.
- Цэцэрлэг, сургууль, цэцэрлэгт хүрээлэн хүртэлх зайнуудын нийлбэрийг хувьсагч болгож оруулсан.
- Хөрш зэргэлдээ газрын дундаж үнэ — 1 байршилд байгаа газруудын нийтэд зарлагдсан стандарт үнийн дундаж (koji_hb)
зэрэг олон хувьсагчдыг шинээр үүсгэсэн.
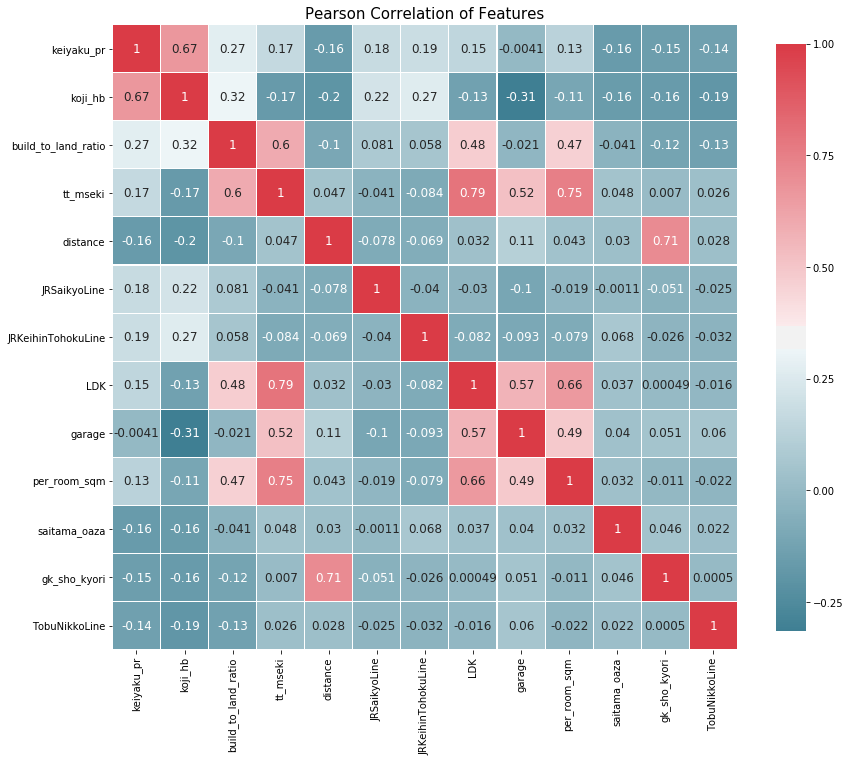
3.3.4. Feature selection — ий хувьд хоорондоо корреляци хамаарал өндөр цөөн хувьсагчийг хасч эцсийн моделийг сургасан.
3.4. Ensemble хийх
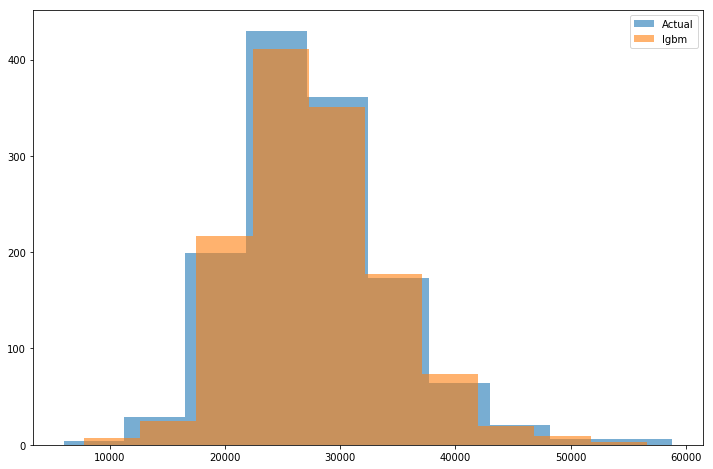
Эцсийн Prediction-г гаргахдаа зурагт үзүүлсэнтэй ижилээр LGBM-н 2 өөр параметртэй моделийн дунджаар submission хийсэн. Олон модель Ensemble хийх нь 1 моделийн үр дүнгээс хамаагүй илүү үр дүн үзүүлж байсан.
Learning Algorithm-н хувьд LGBM буюу Light Gradient Boosting Machineсонгосон нь дараах хэд хэдэн шалтгаантай.
- Сүүлийн үеийн тэмцээнүүдэд LGBM тэргүүлсэн.
- XGboost-тэй харьцуулахад илүү хурдан, үр ашигтай.
- Accuracy буюу таамаглах чадварыг өндөр байхад чиглэсэн tree based алгоритм
- Их хэмжээний өгөгдөл дээр ажиллах чадвартай
Моделынхоо параметрүүдийг tune хийж, зөв сонгох нь бас энэ хэсгийн гол ажлуудын нэг байсан. Хамгийн сайн ажиллаж байгаа моделоо сонгон Training датаны 20% дээр (сургалтанд ашиглаагүй) Validation хийхэд MAE = 1’892’267, MAPE = 7.099 гарсан.
3.5. Эцсийн үр дүн
Эцэст нь сургасан моделоо ашиглан тест дата дээр газрын үнийг таамаглах ажил үлдсэн гэсэн үг. Миний хувьд нийт 82 удаа submission хийсэн бөгөөд Signate өдөрт 5 удаа л submit хийх хязгаартай. Аажим аажмаар алдаагаа бууруулсаар тэмцээн дуусахад 81-р байр буюу top 5%-д багтсан. Хамгийн сүүлийн (82 дахь) submission-ий үзүүлэлтээр public leaderboard дээр 8.72744, private leaderboard дээр 8.89042 оноо авсан.
Ямартай ч энэ тэмцээнд орсноороо олон шинэ зүйл сурч авсан бөгөөд өөр төрлийн бизнесийн дата, асуудал дээр ажиллаж, бусад хүмүүстэй өрсөлдөх нь сонирхолтой байлаа.