“Data Analyst болон Data Scientist – ууд нийт ажлынхаа 60 орчим хувийг датагаа цэвэрлэх, хувиргах болон боловсруулах ажилд зарцуулдаг”
Тэгвэл дата цэвэрлэх үед тулгардаг Outlier утгуудыг Нормал тархалт болон Стандарт хазайлтын тусламжтайгаар хэрхэн өгөгдлөөс утсгах аргачлалыг авч үзье. Хэт өндөр утгуудыг шинжилгээнд ашигласнаар дунджийг хиймлээр өсгөх болон загварын үр дүнд муугаар нөлөөлдөг. Иймд өгөгдлөөс Outlier утгуудыг илрүүлэх, тэдгээрийг засах нь ач холбогдолтой байдаг.

Нормал тархалттай хэмжигдэхүүний 99.7% нь дунджаас доош болон дээш 3 стандарт хазайлттай тэнцэх зайд багтдаг.
Тэгвэл аливаа дата – ны доод болон дээд 5% буюу [Mean – 2*SD] – с доош, [Mean + 2*SD] -с дээш зайд байгаа утгуудыг арилгах замаар Outlier – г засах арга өгөгдөл цэвэрлэх явцад түгээмэл хэрэглэгддэг. Үүнийг Python дээр хэрхэн хийхийг авч үзье.
Шаардлагатай сангуудыг импорт хийх.
import pandas as pd
import matplotlib.pyplot as plt
import seabird as sns
import numpy as np
from scipy.stats import norm
from script import stats
%matplotlib inlineӨгөгдсөн дата: 1000 харилцагчийн зээлийн мэдээлэл.

data['Credit amount'].describe()
# count 1000.000000
# mean 3271.258000
# std 2822.736876
# min 250.000000
# 25% 1365.500000
# 50% 2319.500000
# 75% 3972.250000
# max 18424.000000
# Name: Credit amount, dtype: float64Зээлийн дүнд Outlier утгуудыг байгаа эсэхийг Distribution plot болон Box Plot байгуулан харъя.
sns.distplot(data['Credit amount'], fit=norm);
res = stats.probplot(data['Credit amount'], plot=plt);
fig = sns.boxplot(x='Purpose', y="Credit amount", hue = 'Risk', data=data).set_title('Муу болон сайн зээлүүд, зээл авсан зорилгоор');Тархалтын график, Q-Q plot болон Box Plot – с харвал ‘Credit amount’ хувьсагчид Outlier утгууд байгааг харж болохоор байна.

Зээлийн дүнгийн тархалт. Хар – Нормал тархалтын муруй
Outlier утгуудаас болж Q-Q plot – ын улаан шугам диагонал дээр байрлаж чадахгүй байна.

Q-Q plot. Улаан шугам тэгш өнцөгтийг голоор нь хувааж байвал нормал тархалттай байна гэж үздэг.

Box Plot – ийн дээд болон доод хязгаараас илүү гарсан утгуудыг Outlier утгууд гэж үзэж болно.
Дундаж болон стандарт хазайлт ашиглан Outlier – уудыг устгах.
arr = data['Credit amount']
elements = np.array(arr)
mean = np.mean(elements, axis=0)
sd = np.std(elements, axis=0)
# Outlier - уудыг устгах
data_cleaned = data[data['Credit amount'] > mean - 2 * sd ]
data_cleaned = data[data['Credit amount'] < mean + 2 * sd ]
data_cleaned.describe()
# count 945.000000
# mean 2777.950265
# std 1926.167939
# min 250.000000
# 25% 1338.000000
# 50% 2197.000000
# 75% 3620.000000
# max 8858.000000
# Name: Credit amount, dtype: float64Нийт 1000 өгөгдөл байснаас 945 өгөгдөл үлдсэн буюу 55 өгөгдөл Outlier байсан нь харагдаж байна.
Outlier-уудыг устгасны дараа тархалтын муруйг дахин харъя.


Хэрвээ танд шинжилгээ хийх, загвар байгуулах үед Outlier утгуудыг устгах шаардлага гарвал дээрх аргыг ашиглаад үзээрэй. Үүнээс гадна Outlier-г устгахаас гадна тодорхой Percentile-н утгаар орлуулах мөн боломжтой байдаг.
Data School.
Бусад нийтлэлүүд

Python ашиглан AI аппликейшн хөгжүүлж суръя
Энэ нийтлэлээр бид Python ашиглан хэрэглэгчийн мессежийг ангилдаг жижиг AI-powered аппликэйшн эхнээс нь бүтээнэ. Та дараах зүйлсийг сурна:…

Python Top 10 Hack – Кодоо Ухаалгаар Бичих 10 Арга
Python нь код бичих хурд, ойлгомжтой байдлаараа алдартай. Гэхдээ мэргэжлийн хөгжүүлэгчид эдгээр богино, хэрэгцээтэй 'hack'-уудыг ашиглан Python-г бүр…

Python Virtual Environment үүсгэх
Virtual Environment гэж юу вэ? Virtual Environment (виртуал орчин) нь Python дээр хөгжүүлэгдэх төслийн тусгайлан тохируулагдсан орчин юм.…
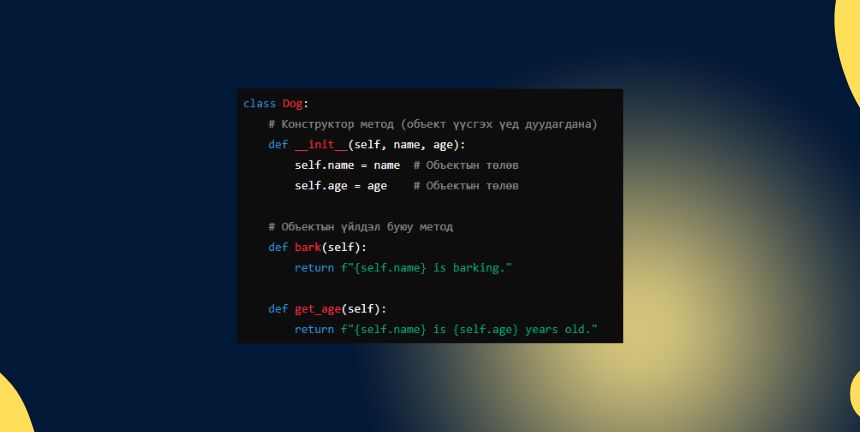
Python Class тухай
Python-ы класс бол объект хандалтат программчлалын үндсэн нэгж юм. Класс нь объектуудын төлөв (Attribute) ба үйлдлүүдийг (Action) тодорхойлдог.…