Хураангуй
Мал аж ахуйн удирдлага нь хөдөө аж ахуйн салбарын чухал хэсэг бөгөөд мал тоолох, малын зан төлвийг хянах үр дүнтэй аргуудыг шаарддаг. Ялангуяа томоохон фермерийн үйл ажиллагааг удирдахад уламжлалт аргууд нь гар ажиллагаа болон цаг хугацаа шаардсан, зардал өндөртэй байдаг. Сүүлийн жилүүдэд компьютерийн харааны (Computer Vision) техникүүд эдгээр процессыг автоматжуулах амжилттай шийдэл болж, бусад улс орнуудын хөдөө аж ахуйн салбарт өргөн ашиглагдаж байна. Энэхүү судалгааны ажил нь компьютерийн харааны алгоритмуудыг ашиглан мал тоолох болон зан төлвийг илрүүлэх систем хөгжүүлэхийг зорьлоо. Санал болгож буй систем нь томоохон фермерүүд эсвэл дроноор авсан зураг, видео бичлэгийг боловсруулах орчин үеийн гүнзгий сургалтын техникүүдийг ашигласан. Faster-RCNN, YOLOv5, YOLOv8 nano болон YOLOv8 medium гэсэн объект таних загваруудыг ашиглан үр дүнг харьцуулсан.
1. Оршил
Мал аж ахуйн удирдлагыг сайжруулах зорилгоор үхрийг автоматаар тоолох болон зан үйлийг хянах компьютерийн хараанд суурилсан системийг хөгжүүлэхэд энэхүү судалгааны зорилго оршино. Үхрийн өвчнийг илрүүлэх, бууруулах шаардлагад тулгуурлан, уг систем нь үхрийн эрүүл мэнд, зан үйлийн талаарх бодит цагийн мэдээллийг өгч, эрт арга хэмжээ авах боломжийг бүрдүүлэн, фермийн үр бүтээмжийг сайжруулахад дэмжлэг үзүүлнэ. Мөн эрүүл мэндийн хяналт, нөхөн үржихүйн болон тэжээлийн удирдлага, үр бүтээмжийг нэмэгдүүлэх, урьдчилсан шинжилгээний аналитик зэргийг хэрэгжүүлэх ач холбогдолтой.
2. Обьект таних загварууд
Объект танилтын аргуудад уламжлалт компьютерийн харааны техникүүд болон гүнзгий сургалтын загварууд багтдаг. Компьютерийн хараанд объект илрүүлэх хоёр стратеги нь нэг шаттай болон хоёр шаттай детекторууд бөгөөд эдгээр нь архитектурын загвар болон объект илрүүлэх, байршуулах дүрс боловсруулах аргуудаараа ялгаатай байдаг.
YOLO (You Only Look Once) загвар
Нэг шаттай детекторууд, үүнд YOLO (Redmon et al., 2016), Single Shot MultiBox Detector буюу SSD (W. Liu et al., 2016), RetinaNet (Lin et al., 2018), болон EfficientDet (Tan et al., 2020) ордог бөгөөд нэг алхамаар хүрээ тэмдэглэл болон ангилалын магадлалуудыг шууд урьдчилан таамаглаж, бодит цагийн боловсруулалтыг зорьдог.
YOLO-ийн олон хувилбарууд хөгжүүлэгдэж байгаа бөгөөд бодит цагийн объект илрүүлэх ажилд өргөнөөр ашиглагддаг. YOLO загварын онцлог нь:
Single-Stage Detection. YOLO нь нэг удаагийн дүрслэлд объектыг илрүүлж, ангилж, хил хязгаарыг тодорхойлдог. Энэ нь нэг удаагийн зураг боловсруулах замаар объектын байршил, ангилалыг илрүүлдэг тул маш хурдан байдаг.
Grid System. Зургийг тодорхой тооны сүлжээнд хувааж, тус бүрийн тор нь объект илрүүлэх үүрэгтэй байдаг. Хэрэв объект нь торны төвд байвал тэр тор нь уг объектыг тодорхойлох зарчимаар ажилладаг.
Regression Problem. YOLO нь объект илрүүлэлтийг регрессийн асуудал гэж үздэг.
Real-time Performance. YOLO загварууд нь хурдан бөгөөд бодит цаг хугацаанд ажиллах чадвартай байдаг нь их хэмжээний видео бичлэгт объект илрүүлэлтийг хийхэд тохиромжтой болгодог.
YOLO загварыг доорх зурагт харуулав (Redmon et al., 2016).

YOLO загварын нэг сул тал нь жижиг объектуудыг урьдчилан таамаглах үед алдаа гаргадаг явдал юм. Энэ асуудлыг шийдвэрлэхийн тулд хоёр шаттай детекторууд, жишээ нь бүсийн конволюцийн нейрон сүлжээ (Region Based Convolutional Neural Network) буюу R-CNN (Girshick et al., 2014), Fast R-CNN (Girshick, 2015) болон Faster R-CNN (Ren et al., 2016) зэрэг нь бүс санал болгох болон объект ангилах гэсэн хоёр үе шатаас бүрдсэн арга барилыг ашиглаж, илрүүлэх нарийвчлалыг нэмэгдүүлдэг.
R-CNN
Зурагт үзүүлсэнчлэн R-CNN нь анхны өгөгдөл буюу зурган дээрээс обьект байх магадлалтай хэсгүүдийг Selective Search арга ашиглан гаргаж авна. Эндээс үүссэн хэсгүүдийг конволюцын сүлжээ рүү (ConvNet) оруулж feature-үүд гаргаж авна. Гаргасан бүс, хэсэг болгон дээр Bounding Box регресс болон Support Vector Machine (SVM) алгоритм ашиглан обьектуудыг таних замаар ажиллана. Энэ аргын нэг дутагдалтай тал нь зурган дээрээс маш олон ConvNet загвар ажиллуулах тул удаан бөгөөд тооцоолох хүчин чадал их шаарддаг.
R-CNN болон Fast-RCNN-ийн тоймыг доорх зурагт үзүүлсэн болно.

Fast R-CNN
Fast R-CNN нь өмнөх хувилбар болох R-CNN-г сайжруулсан хувилбар бөгөөд эхний зурган дээрээс бүсүүд үүсгэхгүйгээр шууд конволюцын сүлжээ ажиллуулж feature-үүд үүсгээд тэндээсээ санал болгох хэсгүүдийг гаргах замаар ажилладаг. Энэ нь өмнөх загвартай ажиллахад олон конволюцын сүлжээ ажиллуулахгүй тул арай хурдан гүйцэтгэх боломж олгодог.

Faster R-CNN
Faster R-CNN (Ren et al., 2016) нь R-CNN цувралын гурав дахь хувилбар бөгөөд өмнөх хоёр загвараасаа илүү хурдтай, үр ашигтай болсон хувилбар юм. Загварын ажиллагааг доорх зурагт харуулав.

Faster-RCNN загварын гол санаанууд
Region Proposal Network (RPN). Faster R-CNN нь RPN нэртэй дэд сүлжээг ашиглан илрүүлэх боломжтой байж болох объектын хэсэг, бүсүүдийг тодорхойлдог. Энэ нь зураг дээрх хамгийн боломжтой объектуудыг олж авахын тулд олон жижиг бүсүүдийг шалгах замаар ажилладаг ба бүсүүдийг нейрон сүлжээний загвараас тодорхойлсноор өмнөх загваруудаас ажиллагааг илүү хурдан болгосон.
Two-Stage Detection. Faster R-CNN нь хоёр шаттай илрүүлэлтийн аргачлалыг ашигладаг. Эхний шатанд RPN нь боломжтой бүсүүдийг тодорхойлдог, дараа нь хоёр дахь шатанд эдгээр бүсүүдийг илүү нарийвчлан шалгаж, объектыг ангилдаг.
Bounding Box Regression. Илрүүлсэн объектын хил хязгаарын байрлалыг нарийн тодорхойлохын тулд хил хязгаарын хэмжээг тохируулдаг регрессийн механизмтай.
Classification and Localization. Объектыг зөв ангилж, хил хязгаарыг зөв тодорхойлох нь Faster R-CNN-ийн гол зорилго юм. Энэ нь илүү нарийвчлалтай танилт хийхэд оршдог.
3. Өгөгдөл
Обьект таних загварыг сургахдаа Roboflow-ийн үхрийн зан төлвийн илрүүлэлт (Version 1) өгөгдлийн санг (CowBehaviorDetection, 2024) ашигласан. Энэ нь 1215 үхрийн зураг, хүрээ тэмдэглэл болон тэдгээрийн шошготой хамт өгөгдсөн. Зургаан төрлийн зан үйлийн ангилалд хээлтүүлгийн үе, идээшилт, хэвтэх, үнэрлэх, зогсолт болон үл хамаарах зан үйлүүд багтсан. Доорх зурагт зарим жишээ зурагнуудыг харуулсан болно.

{
"boxes":[
{
"label":"grazing",
"x":"165.54",
"y":"109.82",
"width":"218.93",
"height":"167.50"
}
],
"height":240,
"key":"GRZ_20.jpg",
"width":361
}Өгөгдөл бэлтгэх болон цэвэрлэх үйл явц
Анхны туршилтын явцад эх өгөгдлийн зарим аннотациуд буруу байсан тул CVAT.ai руу оруулж, бүх аннотациудыг шалгаж, засварласан. Өгөгдлийг цэвэрлэсний дараа дөрвөн төрлийн зан үйлийн ангиллууд (Хээлтүүлгийн үе – Estrus, идээшилт – Grazing, хэвтэх – Lying, зогсолт – Standing) эцсийн загварын сургалтад ашиглагдсан. Мөн сургалтын санд зарим зургуудыг аннотацитай нь нэмсэн.
Аннотацийн жишээг доорх зурагт үзүүлсэн болно.

Өгөгдлийн хуваалт
Өгөгдлийг сургалтын (70%), баталгаажуулалтын (20%), болон тестийн (10%) багцуудад хуваасан. Сургалтын өгөгдлийн санг загвараа сургахад ашигласан бол баталгаажуулалтын багцыг сургалтын явцад загварын гүйцэтгэлийг хянахад ашигласан. Өгөгдлийг бэлтгэсний дараа нийт түүврийн тоо 1229 зураг байсан ба тус бүрийн багц дахь түүврийн тоо доорхи байдлаар тодорхойлогдсон болно.
- Сургалтын багц: 857
- Баталгаажуулалтын багц: 247
- Tестийн багц: 125
4. Үр дүн ба үнэлгээ
Нийт 1229 зурагнаас бүрдсэн эцсийн өгөгдөл дээр загваруудаа сургасан. Faster R-CNN болон YOLO v5 small, v8 nano, болон v8 medium загваруудыг сургасан. Туршилтын тохиргоо болон үр дүнг дараах хэсгүүдэд танилцуулсан болно.
4.1. Загварын тохиргоонууд
Загвар 1. Faster R-CNN.
Model summary:
- Total params: 43,271,528
- Trainable params: 43,046,184
- Non-trainable params: 225,344
- Total mult-adds (G): 559.92
Classes: [‘__background__’, ‘Estrus’, ‘grazing’, ‘lying’, ‘standing’]
Training configurations:
- Model: fasterrcnn_resnet50_fpn_v2
- Number of Epochs: 50
- Batch size = 2
Сургалтын хугацаа: 4 цаг
Загвар 2. YOLO
Train_yaml summary:
- 182 layers
- 7,254,609 parameters
- 0 gradients
Training configurations:
- weights=yolov5s.pt / yolov8n.pt / yolov8m.pt
- image size = 416
- batch size = 16
- Epochs = 200
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Сургалтын хугацаа: 0.8 цаг
Загваруудыг AWS Sagemaker дээр NVIDIA T4 GPU instance ашиглан сургасан.
4.2 Туршилтын үр дүн
Энэхүү хүснэгт нь дөрвөн загварын гүйцэтгэлийн хэмжүүрүүдийг Intersection over Union (IoU) босго дахь дундаж нарийвчлалын (mean Average Precision, mAP) үзүүлэлтээр харуулсан болно.
mAP 0.5 and mAP 0.5:0.95
| Train / Сургалт | Validation / Баталгаажуулалт | |||
| CNN Architecture | mAP 0.5 | mAP 0.5:0.95 | mAP 0.5 | mAP 0.5:0.95 |
| Faster R-CNN | – | – | 0.891 | 0.645 |
| YOLOv5 small | 0.987 | 0.783 | 0.855 | 0.569 |
| YOLOv8 nano | 0.995 | 0.906 | 0.879 | 0.649 |
| YOLOv8 medium | 0.994 | 0.924 | 0.906 | 0.674 |
Баталгаажуулалтын үр дүн:
Average Precision
| CNN Architecture | Estrus | Grazing | Lying | Standing | Нийт |
| Faster R-CNN | 0.688 | 0.586 | 0.663 | 0.646 | 0.646 |
| YOLOv5 small | 0.873 | 0.844 | 0.883 | 0.828 | 0.857 |
| YOLOv8 nano | 0.937 | 0.811 | 0.871 | 0.834 | 0.863 |
| YOLOv8 medium | 0.982 | 0.865 | 0.885 | 0.845 | 0.894 |
Average Recall
| CNN Architecture | Estrus | Grazing | Lying | Standing | Нийт |
| Faster R-CNN | 0.722 | 0.700 | 0.733 | 0.749 | 0.726 |
| YOLOv5 small | 0.765 | 0.745 | 0.795 | 0.860 | 0.791 |
| YOLOv8 nano | 0.832 | 0.702 | 0.872 | 0.895 | 0.825 |
| YOLOv8 medium | 0.889 | 0.771 | 0.846 | 0.860 | 0.841 |
YOLOv8 medium загвар нь сургалт болон баталгаажуулалтын өгөгдлийн сангууд дээрх mAP үзүүлэлтээр бусад архитектуруудаас илүү өндөр үзүүлэлттэй байсан нь энэ объект илрүүлэлтийн ажилд үр дүнтэйг харуулж байна.
Эдгээр үр дүн нь загварын гүйцэтгэл бидний анхны туршилтуудаас (Анхны туршилтын mAP: 0.5 баталгаажуулалтын багц дээр: Faster RCNN 0.805, YOLOv8 Nano 0.805, YOLOv8 Medium 0.836) ойролцоогоор 7-8% сайжирсныг харуулж байна.
4.3. Сургалтын графикууд
Faster R-CNN
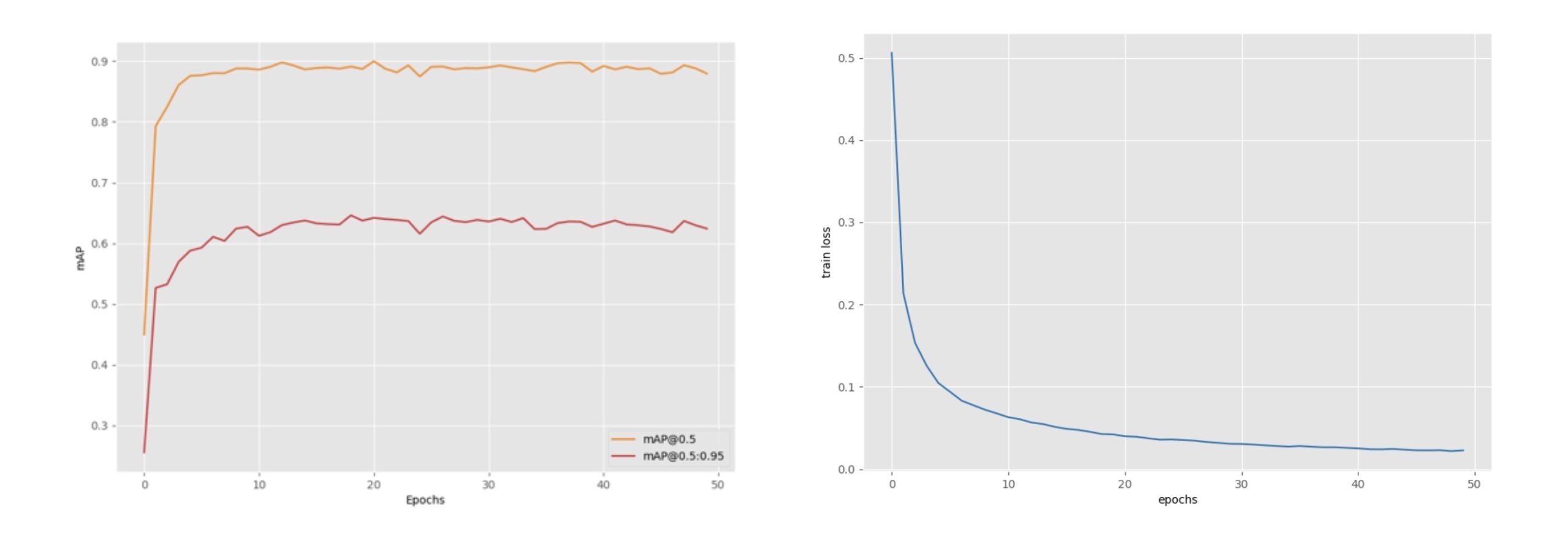
YOLOv5 small

YOLOv8 nano

YOLOv8 medium

4.4. Шинэ зурган дээр таамагласан үр дүн


Django Web Application – ы үр дүнг доор харуулав.

5. Дүгнэлт хэлэлцүүлэг
Энэхүү судалгаа нь үхрийн зан төлөвийг ангилах объект илрүүлэлтийн загваруудыг хөгжүүлэх болон үнэлэх зорилготой байсан. Үүнд дөрвөн объект таних архитектурыг туршсан: Faster R-CNN, YOLOv5 small, YOLOv8 nano, болон YOLOv8 medium. Бүх загварыг ижил зурган өгөгдөл дээр сургасан бөгөөд сургалт болон баталгаажуулалтын өгөгдлийн багцууд дээр үнэлгээг хийсэн.
Загварын үнэлгээ
- Faster R-CNN: IoU 0.5-д баталгаажуулалтын mAP 0.891.
- YOLOv5 small: IoU 0.5-д баталгаажуулалтын mAP 0.855.
- YOLOv8 nano: IoU 0.5-д баталгаажуулалтын mAP 0.879.
- YOLOv8 medium: IoU 0.5-д баталгаажуулалтын mAP 0.906 хүрсэн нь хамгийн өндөр гүйцэтгэлтэй гарсан.
Хязгаарлалт
- Жижиг объект илрүүлэлт. Дунд болон том үхрийн зургууд дээр сургалт хийснээс шалтгаалан загварууд жижиг объектуудыг илрүүлэхэд хүндрэлтэй байсан.
- Давхардсан обьектууд. Обьект давхардал нь машин харааны судалгааны нэг асуудал бөгөөд малын тоо толгойг таних системд мөн нөлөөлөх сул талтай.
Ирээдүйн сайжруулалт
- Жижиг үхрийн зураг буюу объектууд дээр төвлөрсөн олон төрлийн өгөгдлийн санг ашиглан загваруудыг нарийвчлах.
- Өгөгдлийн хомсдолоос шалтгаалан загвар нь үхрийн олон зан төлвийг илрүүлэхэд төвөгтэй байсан. Иймд илүү олон зан төлвийг илрүүлэхэд зориулсан өгөгдөл дээр сургалт хийх нь үр дүнтэй байх магадлалтай.
- Үхрийн өвчний талаарх өгөгдөл цуглуулж загварыг өргөтгөх нь малын өвчнийг илрүүлэхэд илүү нарийвчлалтай үр дүн үзүүлэх боломжтой.
6. Ном зүй
CowBehaviorDetection. (2024). Cow behavior detection dataset [Open Source Dataset]. Roboflow Universe. https://universe.roboflow.com/cowbehaviordetection/cow_behavior_detection-veqgv
Girshick, R. (2015). Fast R-CNN. 2015 IEEE International Conference on Computer Vision (ICCV), 1440–1448. https://doi.org/10.1109/ICCV.2015.169
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. 2014 IEEE Conference on Computer Vision and Pattern Recognition, 580–587. https://doi.org/10.1109/CVPR.2014.81
Jacob, S., & Francesco. (2024). What is YOLOv8? The Ultimate Guide. https://blog.roboflow.com/whats-new-in-yolov8/
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A. C. (2016). SSD: Single Shot MultiBox Detector (Vol. 9905, pp. 21–37). https://doi.org/10.1007/978-3-319-46448-0_2
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You Only Look Once: Unified, Real-Time Object Detection (arXiv:1506.02640). arXiv. http://arxiv.org/abs/1506.02640
Ren, S., He, K., Girshick, R., & Sun, J. (2016). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arXiv:1506.01497). arXiv. http://arxiv.org/abs/1506.01497
Tan, M., & Le, Q. V. (2020). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (arXiv:1905.11946). arXiv. http://arxiv.org/abs/1905.11946
Tan, M., Pang, R., & Le, Q. V. (2020). EfficientDet: Scalable and Efficient Object Detection (arXiv:1911.09070). arXiv. http://arxiv.org/abs/1911.09070
Бусад нийтлэлүүд

Python ашиглан AI аппликейшн хөгжүүлж суръя
Энэ нийтлэлээр бид Python ашиглан хэрэглэгчийн мессежийг ангилдаг жижиг AI-powered аппликэйшн эхнээс нь бүтээнэ. Та дараах зүйлсийг сурна:…

MCP ба Agentic AI: Дараагийн үеийн хиймэл оюуны архитектур
Сүүлийн жилүүдэд хиймэл оюун (AI) нь шийдвэр гаргадаг, зорилго тодорхойлдог, өөрөө гүйцэтгэдэг систем рүү шилжиж байна. Энэ шилжилтийн…

NVIDIA-ийн 2025 оны 12 сар ба CES 2026-ийн гол үйл явдлууд
“Consumer Electronics Show (CES) 2026” — Дэлхийн хамгийн том, хамгийн нэр хүндтэй технологийн үзэсгэлэн (тэргүүлэх технологийн худалдаа, инновацийн…

2025 оны 12 сарын хиймэл оюун ухааны гол шинэчлэл, үйл явдлууд
GPT-5.2 — OpenAI-ийн шинэ үеийн AI загвар 2025 оны 12 сарын 11-нд OpenAI-ийн GPT-5.2 загвар албан ёсоор гарч,…