Их Өгөгдлийн Гол Ойлголтууд
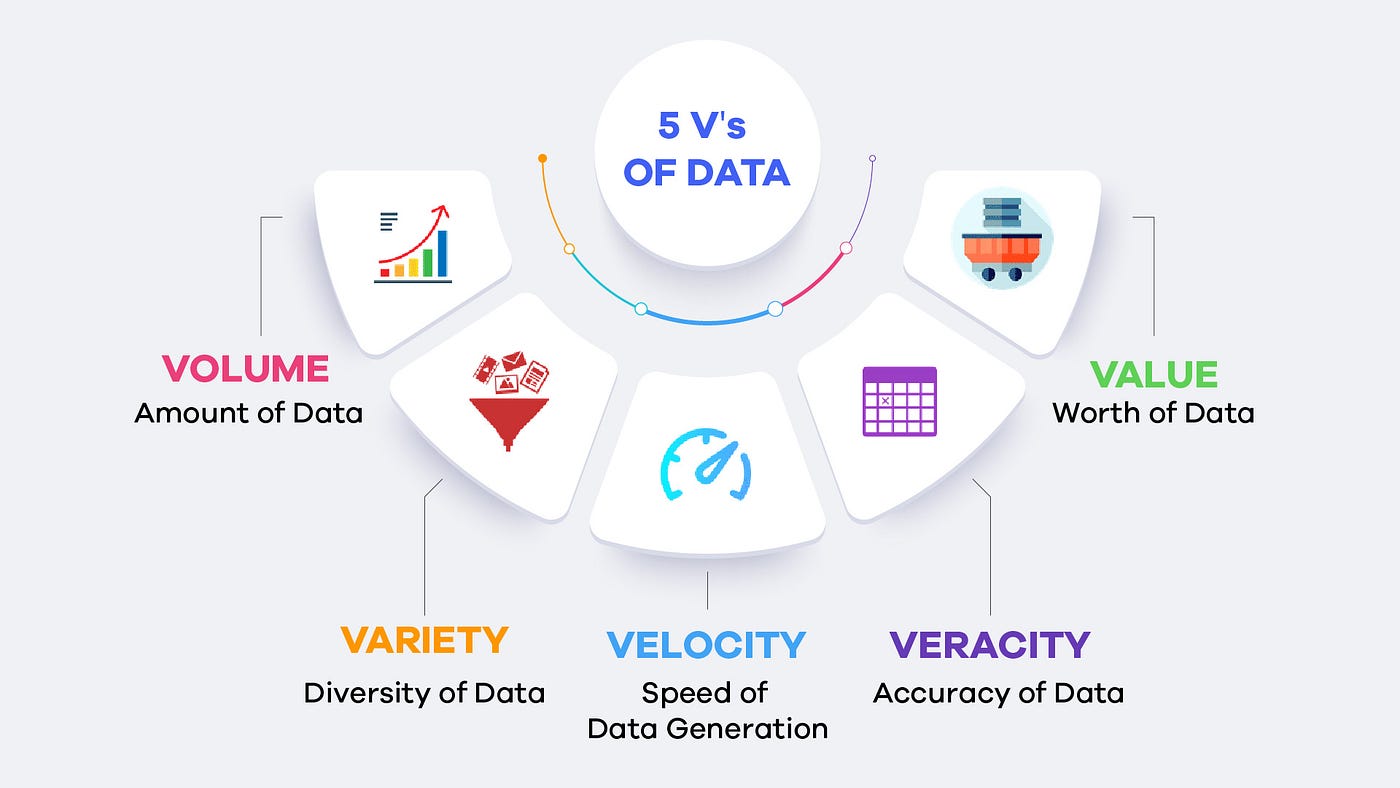
Их өгөгдөл (Big Data) гэдэг нь уламжлалт өгөгдлийн менежмент системүүдээр боловсруулж, хадгалж, шинжлэх боломжгүй асар их хэмжээтэй, өндөр хурдтай, олон төрлийн өгөгдлийг хэлнэ. Их өгөгдлийг дараах “5V” шинж чанараар тодорхойлдог:
- Volume (Хэмжээ): Өгөгдлийн хэмжээ маш их (террабайт, петабайт эсвэл түүнээс дээш).
- Velocity (Хурд): Өгөгдлийн үүсэх, боловсрох хурд өндөр (жишээ нь, бодит цагийн өгөгдөл).
- Variety (Төрөл): Өгөгдлийн төрөл олон янз (бүтэцлэгдсэн, бүтэцлэгдээгүй, хагас бүтэцлэгдсэн).
- Veracity (Үнэн зөв байдал): Өгөгдөл нь үнэн бодитой байдлыг хангаж байх.
- Value (Үнэ цэнтэй байдал): Өгөгдлийн тодорхой үнэ цэнтэй байх шинж чанар.
Жишээ
Жишээ 1: Нийгмийн Сүлжээ
- Өгөгдлийн хэмжээ: Хэрэглэгчдийн нийтлэл, сэтгэгдэл, зураг, видео гэх мэт олон төрлийн өгөгдөл.
- Өгөгдлийн хурд: Бодит цагийн шинэчлэлт, шуурхай хариу үйлдэл.
- Өгөгдлийн төрөл: Текст, зураг, видео, аудио.
Жишээ 2: Интернэт Худалдаа
- Өгөгдлийн хэмжээ: Худалдан авалтын түүх, бүтээгдэхүүний мэдээлэл, хэрэглэгчдийн тойм.
- Өгөгдлийн хурд: Захиалгын статусын шинэчлэлт, бодит цагийн борлуулалтын өгөгдөл.
- Өгөгдлийн төрөл: Текст, тоон өгөгдөл, зураг.
Ашиглагддаг Технологиуд
1. Hadoop
- Тодорхойлолт: Их өгөгдлийг хадгалах, боловсруулах зориулалттай, нээлттэй эхийн программ хангамж.
- Гол бүрэлдэхүүн хэсгүүд:
- HDFS (Hadoop Distributed File System): Хуваарилагдсан файл систем.
- MapReduce: Өгөгдлийг хуваах, боловсруулах программчлалын загвар.
# Hadoop-ийг ажиллуулах жишээ (pseudo-distributed mode)
$ start-dfs.sh
$ start-yarn.sh2. Spark
- Тодорхойлолт: Hadoop дээр суурилсан, их өгөгдлийг боловсруулдаг хурдан, нээлттэй эхийн программ хангамж.
- Давуу тал: In-memory (санах ойд) өгөгдлийг боловсруулах, өндөр хурдтай ажиллах.
from pyspark import SparkContext
sc = SparkContext("local", "Simple App")
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
print(distData.reduce(lambda a, b: a + b))3. NoSQL
- Тодорхойлолт: Уламжлалт RDBMS (relational database management systems)-ээс ялгаатай, өгөгдлийг уян хатан, хурдан боловсруулах боломжтой мэдээллийн сангийн системүүд.
- Жишээ:
- MongoDB: Документ суурьтай мэдээллийн сан.
- Cassandra: Хуваарилагдсан мэдээллийн сан.
# MongoDB ашиглах жишээ
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.mydatabase
collection = db.mycollection
# Баримт нэмэх
collection.insert_one({"name": "Alice", "age": 30})
# Баримт хайх
for person in collection.find({"age": {"$gte": 25}}):
print(person)4. Data Processing Tools
- Apache Kafka: Өгөгдлийн урсгалыг бодит цагт боловсруулах систем.
- Apache Flink: Бодит цагийн болон багц өгөгдлийг боловсруулах.
# Kafka ашиглах жишээ (producer)
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('my-topic', b'Hello, Kafka!')
producer.close()Дүгнэлт
Их өгөгдөл нь асар их хэмжээтэй, өндөр хурдтай, олон төрлийн өгөгдлийг багтаасан мэдээллийг удирдах, шинжлэх үйл явц юм. Үүнийг хэрэгжүүлэхэд зориулсан Hadoop, Spark, NoSQL, Kafka зэрэг олон төрлийн технологиуд ашиглагддаг. Эдгээр технологиуд нь их өгөгдлийг хурдан, уян хатан, үр дүнтэй боловсруулах боломжийг олгодог.
Эх сурвалж
Hadoop:
- Apache Hadoop. https://hadoop.apache.org/
- White, T. (2015). “Hadoop: The Definitive Guide.” O’Reilly Media.
Spark:
- Apache Spark. https://spark.apache.org/
- Zaharia, M., et al. (2016). “Spark: The Definitive Guide.” O’Reilly Media.
NoSQL:
- MongoDB. https://www.mongodb.com/
- Cassandra. https://cassandra.apache.org/
- Strauch, C. (2011). “NoSQL Databases.” Lecture Notes, Stuttgart Media University.
Data Processing Tools:
- Apache Kafka. https://kafka.apache.org/
- Apache Flink. https://flink.apache.org/
- Kreps, J., et al. (2011). “Kafka: A Distributed Messaging System for Log Processing.” LinkedIn.
Big Data Concepts:
- Manyika, J., et al. (2011). “Big data: The next frontier for innovation, competition, and productivity.” McKinsey Global Institute.
- Marr, B. (2016). “Big Data: Using SMART Big Data, Analytics and Metrics To Make Better Decisions and Improve Performance.” Wiley.
Бусад нийтлэлүүд

Өгөгдлөөс мэдлэг гарган авах аргачлал (KDD)
Дээрх диаграмм нь өгөгдлөөс мэдлэг гарган авах (Knowledge Discovery in Databases, KDD) үндсэн үе шат, дамжлагыг харуулж байна.…
Дата анализ хийхэд гардаг түгээмэл 10 алдаа
Өгөгдөлд суурилсан шийдвэр гаргалт нь бизнес, шинжлэх ухаан, технологийн салбарт чухал үүрэг гүйцэтгэдэг. Гэсэн хэдий ч, дата анализ…

CRISP-DM аргачлалын тухай
CRISP-DM (Cross-Industry Standard Process for Data Mining) нь өгөгдөл олборлолтын төслийн хэрэгжилтэд өргөн хэрэглэгддэг аргачлал юм. Энэхүү аргачлал…

Өгөгдөл ба түүний төрлүүд
Өгөгдөл гэж юу вэ? Өгөгдөл гэдэг нь мэдээлэл, тоон утга, баримтуудын цуглуулга юм. Энэ нь тодорхой нэг зорилгоор…